-
Vision-Language Pretrained Model 리뷰 - BLIP, BLIP2ML&NLP 2023. 8. 31. 22:41
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
International Conference on Machine Learning. PMLR, 2022
https://arxiv.org/abs/2201.12086https://huggingface.co/docs/transformers/main/model_doc/blip
1. Intorduction
기존 Vision-Language Pretraining 모델 들의 한계
- 모델 측면 : Encoder-based 모델은 image captioning 과 같은 텍스트 생성 Task 에서 덜 직관적이며, Encoder-decoder 모델들은 Image-Text Retrieval에 효과적으로 적용되지 못했다.
- 데이터 측면 : SOTA 모델들(CLIP, ALBEF등)은 Web 을 통해서 Large-Scale 로 데이터를 모았다. Large-Scale 이어서 성능향상에 기여를 하긴 하지만 이는 상당히 Noisy 하다.
BLIP 에서 제안 하는 것
- Multimodal mixture of Encoder-Decoder (MED) : Unimodal encoder, image-grounded text encoder, image-grounded text decoder 가 조합된 새로운 구조 제시
- Captioning and Filtering (CapFilt) : Noisy 한 web 데이터를 정제/증강하여 학습하는 방식.
2. Model

구조는 위그림과 같습니다. 이미지/텍스트 Unimodal Encoder 는 각각 ViT/BERT 구조를 사용하였다고 합니다. Image-grounded Text Encoder 와 Decoder 는 이미지 hidden state 로 cross attention 하는 구조만 다릅니다. 효율적인 학습을 위해 이 encoder 와 decoder 는 "Self-Attention" 레이어만 제외하고 파라미터를 공유한다고 합니다. 이유는 encoder는 양방향, decoder 는 단방향으로 attention을 받기에, self-attention 레이어에서 encoder 와 decoder 의 차이가 가장 잘 caputred 되기 때문이라고 합니다.
학습 Loss 로는 3가지를 사용 하였습니다.
Image-Text Contrastive Loss (ITC) : CLIP 등에서 사용된 positive image-text pair의 image representation과 text reprsentation의 유사도를 높게 학습시키는 방식입니다. 두 feature space 를 align 시키는 효과도 있고 Vision-Language Task 에서 효과성을 입증해온 방법입니다. 이 loss 를 계산할 때 ALBEF 에서 제안된 momentum encoder 를 활용한 soft-label 로 학습했다고 합니다.
Image-Text Matching Loss (ITM) : Image-grounded text encoder 를 학습시키는 Loss 로, 주어진 Image - Text 쌍이 매치되는지 binary classification task 입니다. Informative 한 Negative Pair 를 선택하는 전략으로 ITC 를 계산할 때 가장 높은 similarity 를 가지는 pair 를 선택하였다고 합니다.
Language Modeling Loss (LM) : Image-grounded text encoder를 학습시키기 위한 다음 단어를 예측하는 loss 입니다.
3. Captioning and Filtering

논문에서 제안한 웹데이터를 Bootstrapping(정제/증강) 하는 방식은 다음과 같습니다
STEP 1. 먼저 고품질 데이터셋(human-annotated, COCO 데이터셋) + 웹 데이터로 위에 설명한 모델을 pre-train 합니다.
STEP 2. Image-grouonded Text Encoder 와 Text Decoder 를 고품질 데이터셋만 이용해 fine-tuning 합니다.
STEP 3. (증강) 웹 데이터의 이미지를 Step 2의 Text Decoder 에 입력으로 넣어 새로운 text caption 을 생성합니다.
STEP 4. (정제) 웹 데이터에 존재하던 페어와 STEP3 에서 만들어진 페어를 Step2 의 Text Encoder 에 입력으로 넣어 높은 점수를 받은 Pair 만 걸러냅니다.
이 과정을 통해 새로운 데이터셋을 만들고, 모델을 다시 Pretrain 시켰다고 합니다.
4. 결과

위 테이블에서 보이듯이 Captioning and Filtering 데이터 bootstrapping 전략이 효과가 있음을 확인하였습니다.
또한, 해당 BLIP 모델이 image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), VQA (+1.6% in VQA score). Task 에서 SOTA 보다 좋은 성능을 달성했다고 합니다.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
International Conference on Machine Learning(ICML). 2023개요
Vision-Langue 모델을 pretrainig 할 때, computation cost를 줄이고 잘 학습된 기존 Unimodal pre-trained 모델 ( ViT, T5,GPT, ...) 의 catastrophic forgetting 을 방지하고자 하면 Unimodal pre-trained 모델은 freezing 하는 것이 좋습니다.
그러나 freezing 하는 방식은 cross-modal alignment, modality gap 을 줄이는 것이 도전적입니다.
이에 BLIP2 에서는 이미지 표현을 Query로 전환하여 학습하는 Querying Transformer를 제안합니다.
구조 및 학습
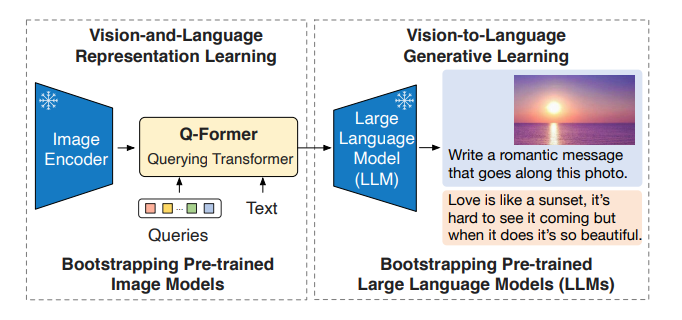
Stage1. Vision-and-Language Representation Learning

여기서 Queries 란 32*hidden_state 짜리 학습가능한 parameter 입니다. 텍스트 입력으로 생각한다면, sequence length 가 32 라고 생각하시면 됩니다. 이 Query Encoder 가 Frozen 된 Image Encoder 와 cross-attention 을 하면서, 32*hidden state 짜리 이미지 표현 방식을 학습합니다. Query Encoder 와 Text Encoder 는 parameter 를 Share 하고, Loss 에 따라 우측과 같이 attention mask 만 달라지는 형태 입니다.
Stage 2. Vision-to-Language Generative Learning

Query Encoder 를 Fully connected 레이어로 변환하여 Frozen 된 LLM 에 입력(OPT,T5)으로 넣고, 이미지 기반 텍스트를 잘 생성하도록 Q-Former 와 Fully Connected 레이어를 학습시킵니다.
결과
여러가지 vision-language task 에서 SOTA 를 달성했다고 합니다.

또한 Pre-trained 된 BLIP2 모델에서 zero-shot 으로 위와 같이 이미지에 대해 설명하는 대화가 가능하다고 합니다.
(해당 예시 Frozen Uni-modal 모델로는 각각 / ViT-g and FlanT5XXL 을 사용)
'ML&NLP' 카테고리의 다른 글
Chameleon : 메타의 새로운 Multimodal LLM (0) 2024.06.12 UniS-MMC: Multimodal Classification via Unimodality-supervisedMultimodal Contrastive Learning 논문 리뷰 (0) 2024.06.05 E5 Text Embedding 시리즈 논문 및 구현 설명 (0) 2024.03.06 [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning (0) 2023.11.15 PCGrad - Gradient Surgery for Multi-Task Learning 논문 설명 및 구현 (1) 2023.07.21