-
[MoCo] Momentum Contrast for Unsupervised Visual Representation LearningML&NLP 2023. 11. 15. 18:28
Paper : Momentum Contrast for Unsupervised Visual Representation Learning. CVPR. 2020
Code : https://github.com/facebookresearch/moco
요약
Unsupervised Contrastive Learning 할 때, Large Negative Sample 이 성능에 중요하다. MoCo는 queue를 활용해 비약적으로 많은 Negative Sample을 효과적으로 사용할 수 있게 한 기법
읽게 된 배경
Multimodal 관련 representation learning 볼 때, MoCo 얘기가 많이 나왔고 또 인용이 엄청 많이 된 Paper라 읽어 보게 됨.
Due to the use of a frozen image encoder, we can fit more samples per GPU compared to end-to-end methods. Therefore, we use in-batch negatives instead of the momentum queue in BLIP. - BLIP2, 2023
However, it requires a large batch size to yield high performance, which is computationally prohibitive. Moco (He
et al., 2020a) addresses this issue by maintaining a queue of data - KFCNet, 2021
Introduction
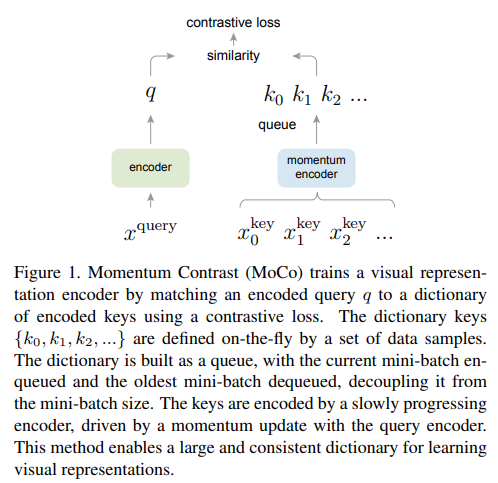
- Unsupervised representation learning is 은 BERT와 GPT가 보여 주듯이 NLP 에서 큰 성공을 거두었다. 하지만, vision 에서는 아직 Supervised Method 가 강력하다
- 그 이유는, Language는 word 와 같은 discrete 한 signal space를 가지고 있어, tokenized dictionary 구축이 용이하다. 반면, vision 에서는 이와 다르게 continuous 하고 high-dimensional 한 space 를 표현할 수 있는 "dictionary"를 구축이 어렵기 때문일 것이다.
- 최근 연구들이 contrastive loss를 활용하여 visual representation learning 에서 상당한 효과를 보여왔다. 다양한 동기로부터 이 연구들이 진행되었겠지만, 결국 이 방식들은 "dictionary"를 잘 구축하기 위한 접근법으로 볼 수 있다.
- Dictionary의 "Keys" 들은 data( e.g. images or patches) 에서 sampling 되고, encoder network에 의해 벡터로 표현된다.
- Unsupervised learning 은 encoded된 "query" 가 matching 되는 key 의 representation 과는 유사하게, 다른 key들과는 다르게 표현되도록 학습한다.
- 이 학습 방식은 contrastive loss 를 줄여나가는 형태로 표현된다.
- 이 관점에서, 좋은 dictionary에 요구되는 것들은 다음과 같다.
- Large : a larger dictionary may better sample the underlying continuous, highdimensional visual space
- Consistent : 학습이 진행되면서 encoder 의 파라미터도 바뀌기 때문에 dictionary 에 들어있는 key들의 representation(encoded key)는 최신화 되어야 한다.
- 그러나 현재까지 나와있는 방법들은 두가지 측면에서 각각 부족함 점들이 있다.
- --> MoCo 는 queue를 활용해, Large 하고 Consistent 한 Key Representation 을 활용할 수 있는 방법을 제시한다.
* MoCo 는 다른 Unsupervised 방법론과 비교해, linear classification in the ImageNet Task(= 파라미터 고정한채 Linear layer 한개만 ImageNet 에서 fine-tuning 해서 성능 비교하는 것) 에서 좋은 성능을 보인다.
* Moco 는 Image-Net Supervised Training과 비교했을 때 몇몇 downstream task 에서 좋은 성능을 보였다.
Method
Method - 1) Loss

먼저 Loss Function 은 위와 같습니다. q 와 k 는 각각 encoded 된 이미지 representation 이고, k+ 는 Postivie Pair, 나머지 k 들은 Negative Pair를 나타냅니다.
Method - 2) Algorithm
MoCo 의 방식은 다음과 같습니다.
1. 일단 query encoder 와 key encoder 는 다른 파라미터를 가지는 서로다른 encoder 입니다.
2. N 개의 서로다른 이미지에 대해서 각각 query encoder 와 key encoder로 representation 을 추출합니다.
3. key enocder로 표현된 벡터들은 queue(=dictionary) 에 저장해줍니다.
4. queue(dictionary) 가 꽉찼으면(논문에선 최대 64K 까지 실험), 가장 과거에 들어왔던 key representation 들은 제거해 줍니다.
5. queue(dictionary) 에 들어있는 모든 encoded key representation이 위 contrastive loss에서 negative pair로 쓰입니다.
이 거대한 queue를 어떻게 관리하냐 하면,
1. 기본적으로 dictionary에 들어가는 표현을 추출하는 key encoder 는 back propagation을 받지 않습니다. 그래서 dictionary 는 (dictionary 크기 * emb size )의 실수값만을 가지고 있으면 됩니다.
2. 그렇다고 key encoder가 항상 고정적인 건 아니고 아래와 같이 업데이트 한다고 합니다.

3. 즉 gradient update를 받는 query encoder 의 parameter를 가져오는 형태입니다. 이 때 m은 큰 값이여야 key encoder가 smoothly 하게 업데이트 되어 학습이 잘되고 좋은 성능을 보인다고 합니다. 0.9~0.9999 정도 를 실험하였습니다.

Method - 3) Details
Positive/Negatve Pair 이미지 가져오는 법 : 같은 이미지로부터 서로다른 형태의 이미지 조작( resize-crop 등 )을 받은 Pair를 positive pair로 사용했다고 합니다. Negative Pair는 randomly 다른 이미지에서 온 이미지들이면 negative로 선정
Encoder : ResNet 류의 CNN 기반 네트워크를 사용했다고 합니다.
Shuffling BN : Batch Normalization 을 사용하면, model 이 good representations을 배우는데 방해가 된다고 합니다. 그 이유는 샘플들 간의 intra-batch communication among samples 이 정보를 leaks(?) 하게 되어 모델이 easy solution 을 배우기 때문이라고 합니다. 그래서 GPU 에 batch를 나누어줄때 섞고 뭐 이런저런 방법을 써서 해결했다고 하는데 이해가 잘 안 갔습니다.
Experiment

먼저 end-to-end 와 memory bank 기법과 비교 하였는데, end-to-end는 일반적인 mini-batch 안에 다른 pair 에 속한 이미지들이 negative pair 가 되는 방식입니다. memory bank 는 moco 직전에 나온 방식으로 똑같이 dictionary를 활용하기는 하는데 이 dictionary를 업데이트 하는 방법이 moco 가 더 좋은 방법이라 합니다.

먼저 ImageNet Linear Classification Protocol Task(파라미터 고정시켜놓고, linear 레이어 하나만 fine-tuning) 에서 다른 방식들보다 좋은 것을 알 수 있습니다. K-1=Negative Sample의 개수 입니다. end-to-end 방식은 in-batch 에서만 negative를 가져오는 방식이기 때문에 negative sample을 늘리는데 한계가 있어, 8개 v100 GPU 에서 1024 까지만 실험이 가능했다고 합니다.

Encoder의 파라미터 수를 변화해가면서 Image Net Linear Classification Protocol Task를 수행했을 때 기존의 다른 Unsupervised 방식들과 비교했을 때 대부분 좋은 성능을 보였다고 합니다.

좋은 representation인지 평가하는 방식 중에 대표적인, downstream task 로 fine-tuning 했을 때 성능이 좋은가도 실험을 해보았다고 합니다. vision 쪽 지식이 없어서 모르겠지만 몇몇 task 에서 ImageNet Supervised 로 학습된 것보다 성능이 좋았다고 합니다.
'ML&NLP' 카테고리의 다른 글
Chameleon : 메타의 새로운 Multimodal LLM (0) 2024.06.12 UniS-MMC: Multimodal Classification via Unimodality-supervisedMultimodal Contrastive Learning 논문 리뷰 (0) 2024.06.05 E5 Text Embedding 시리즈 논문 및 구현 설명 (0) 2024.03.06 Vision-Language Pretrained Model 리뷰 - BLIP, BLIP2 (0) 2023.08.31 PCGrad - Gradient Surgery for Multi-Task Learning 논문 설명 및 구현 (1) 2023.07.21