-
UniS-MMC: Multimodal Classification via Unimodality-supervisedMultimodal Contrastive Learning 논문 리뷰ML&NLP 2024. 6. 5. 21:26
Zou et al., UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning. ACL Findings. 2023
Introduction
배경
멀티모달 Representation, 구체적으로는 멀티모달 Classification 문제를 푸는 방법에 대한 논문이고 실험은 텍스트 + 이미지 멀티모달 대해서 진행되었습니다.
멀티모달 문제를 푸는 가장 대표적인 방식은, Uni-Modal 의 Large Pretrained Model 등을 활용하여 각 Uni-Modal Representation을 잘 조합하고 학습하는 것입니다. 이 방법에는 각 Modality의 Feature를 Fusion 하는 aggregation-based method가 대표적입니다. 다만 aggregation-based method 는 modality 간의 상관관계를 무시하는 경향이 있어, 이를 풀고자 alignment-based method 들도 추가적으로 제안되어왔습니다. 대표적으로 CLIP 에 나온 기법과 같이 같은 대상을 나타내는 서로 다른 modality 의 representation 을 contrastive learning 등을 통해 align 시켜주는 형태입니다.
문제 제기
실제 in-the-wild의 멀티 모달 객체, 예를 들어 상품정보나 포스팅등을 보면, 이미지 또는 텍스트만 따로 봤을 때 정확히 무엇을 나타내는지 모르는 경우가 제법 있습니다. 즉, 이미지 텍스트 둘다를 봐야 정확히 무엇을 나타내는지 알 수 있는 것, 텍스트에는 충분한 정보가 담겨있지만 이미지는 모호한 이미지가 담겨있는 경우, 또 그 반대의 경우 등이 있습니다.

그러나 기존 방법들은 이와 같은 in-the-wild dataset에서 각각의 modality를 동등하게 취급하여 각기 다른 modality의 역할을 무시하는 경향이 있다고 합니다. 불충분한 정보를 가진 unimodal represenation은 final decision에 나쁜 영향을 미치고, 좋은 멀티모달 표현을 생성하는데에 어려움을 가지게 합니다.
이에 " different contributions from the modailities" 문제를 풀기위해 저자들은 UniS-MMC 란 방법론을 제안합니다. 이는 representation들을 좀 더 효과적인 modality 에 align 하는 방식이며, uni-modality의 prediction 을 weak supervision으로 활용합니다.
Method

본 논문에서 제안하는 전체 Architecture 기본 구조
먼저 각각의 Uni Modal Encoder 만 활용해서 각각 Cross Entropy Loss를 적용합니다. (L_text, L_image). 두번째로, 각 Uni Modal Encoder 에서 나온 벡터를 Concat 한 후 Classifier 를 붙여 CrossEntropy 로스를 적용합니다. 이 Loss 들을 다 합쳐 즉, L_text + L_image + L_multimodal 을 기본 학습 구조로 합니다.
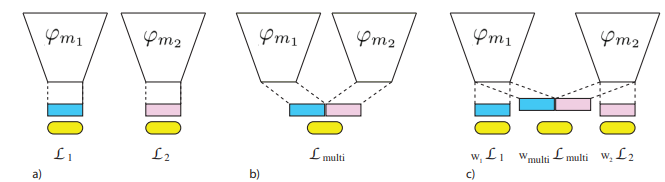
Wang et al., 2020 이와 같이 Uni Modal Losses + Multi Modal Loss 를 Joint 하게 학습 하면 좋은 성능을 보이는 것은 Wang et al., What makes training multi-modal classification networks hard?. CVPR. 2020 등에서도 제시 되었었습니다. 이 논문에서 loos별 coefficient(w1,...)를 주는 방식과 자세한 원리를 분석하였는데 아직 자세히 이해하지는 못하였습니다. 직관적으로 특정 Modality에 overfit 되는 것을 방지한다 정도로만 생각하고 있습니다.
+UniS-MMC
먼저 각 데이터 Sample을 크게 3가지 유형으로 나눕니다.
- 1) Positive-Pair : 두 Modality(Text, Image) 각각이 모두 정답을 예측한 경우
- 2) Semi Positive-Pair : 두 Modality 중 하나만 정답을 맞춘 경우
- 3) Negative-Pair : 두 Modality가 모두 오답을 예측한 경우
저자들은 3)의 경우는 각각의 Uni Modal Representatione 들이 좀 더 보완적인 정보를 학습하도록 하기 위해 서로 달라지도록 학습되어야 한다고 합니다. " It helps to a higher possibility of correct multimodal prediction ". 2)의 경우에는 Informative 한 (정답을 맞춘) Modality 의 representation 에 다른 Modality 가 align 되도록 해야 한다고 합니다.
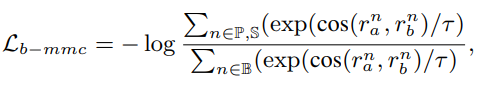
이 의도를 반영하여 UniS-MMC Contrastive Loss 는 이와 같습니다. Positive Pair 와, Semi-Positive Pair 에 있는 uni modal representation 이 유사해지도록 학습하는 contrastive loss 입니다. 이 때 Semi-Positive 와 Postive 의 차이점은, Semi-Positive 일 경우 정답을 맞춘 modality 의 representation은 detach 해서 오답인 modality 쪽만 update 하도록 합니다.
최종적으로, 학습 Loss 는 아래와 같습니다.
Loss = L_text + L_image + L_multimodal + w*L_mmc
w 는 상수값으로 0.1을 사용했습니다.
Experimental Result
실험은 Image + Text Multimodal 분류 데이터셋인 Food101 과 N24News 데이터셋에 대해서 진행되었습니다.

먼저 각 Loss 의 효과에 대한 실험 결과 입니다. L_uni 는 Unimodal Loss 를 추가해 학습하였을 때의 결과 입니다. 이게 가장 효과가 좋아 보입니다. C 부분은 이 논문에서 제안한 Contrastive 기법을 추가하였을 때의 결과 입니다.

다른 방법들과의 비교 입니다. 여기서 UnSupMMC 와 SupMMC 는 기존에 다른 Image-Text Contrastive Learning 에서 하듯이 같은 data sample 을 나타내는 (Sup의 경우에는 같은 class) Image와 Text representation 의 유사도가 높도록 contrastive learning 을 하는 방식들입니다.
'ML&NLP' 카테고리의 다른 글
2024 DoLa NLP Seminar (0) 2024.08.30 Chameleon : 메타의 새로운 Multimodal LLM (0) 2024.06.12 E5 Text Embedding 시리즈 논문 및 구현 설명 (0) 2024.03.06 [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning (0) 2023.11.15 Vision-Language Pretrained Model 리뷰 - BLIP, BLIP2 (0) 2023.08.31