-
Chameleon : 메타의 새로운 Multimodal LLMML&NLP 2024. 6. 12. 22:13
원본 자료/Links
Paper
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Repository
https://github.com/facebookresearch/chameleon?tab=readme-ov-file
Blogs
https://medium.com/@saadsalmanakram/chameleon-metas-new-pioneering-multi-modal-ai-model-8b3bbed71585
https://openpage.store/blog/2024/05/24/ai-info-meta-llm-chameleon/
Chamelon이 잘하는 것
" We present Chameleon, a family of mixed-modal foundation models capable of generating and reasoning with mixed sequences of arbitrarily interleaved textual and image content "
예시는 아래 와 같이 바나나 사진 주고, "이걸로 어떤 빵을 만들 수 있어? 조리법이랑 사진을 보여줘" 하면 조리법도 상세히 설명하고, 사진도 생성하는 답변을 줌

Chamelon이 못 하는 것
GPT-4O 랑 다르게 이미지 속에 글자 인식/생성은 잘 못하는 듯.
- A core weakness of our tokenizer is in reconstructing images with a large amount of text, therefore upper bounding the capability of our models, when it comes to heavy OCR-related tasks.
- ... partially because our prompts focus on the mixed-modal output, certain visual understanding tasks, such as OCR or Infographics (i.e., interpreting a given chart or plot), are naturally excluded from our evaluation.
Chamelon 특징
Early Fusion Token-based mixed-modal model
Image, Text representation 을 각각 표현하고 나중에 합치는 것이 아닌 early-fusion 방식을 채택했다고 함. 이미지 텍스트를 같은 token space 로 표현하는 그런 느낌?
- Gemini, GPT4o(추정) 도 이 구조를 사용했다고 한다
- "... early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence "

- Image Tokenization : 512 × 512 를 1024 개의 token 으로 표현. 아마 16x16 patch 로 자르는듯? 각각의 token은 8192 크기의 codbook 에서 온 discrete한 token이다.
- image discrete token, codebook 개념 검색해보니 막 diffusion 나오고... 하는데 이쪽을 팔로우업 못해서 잘 이해가 안감.
- Tokenizer : BPE tokenizer를 학습 시켰다.위에 말한 8192이 image token 도 포함해서 65,536의 vocab 을 가진다.
Chamelon 성능
Chamelon 성능1
멀티 모달 컨텐츠 생성/이해 평가에서 GPT4/Gemni 보다 좋은 평가를 받았다!
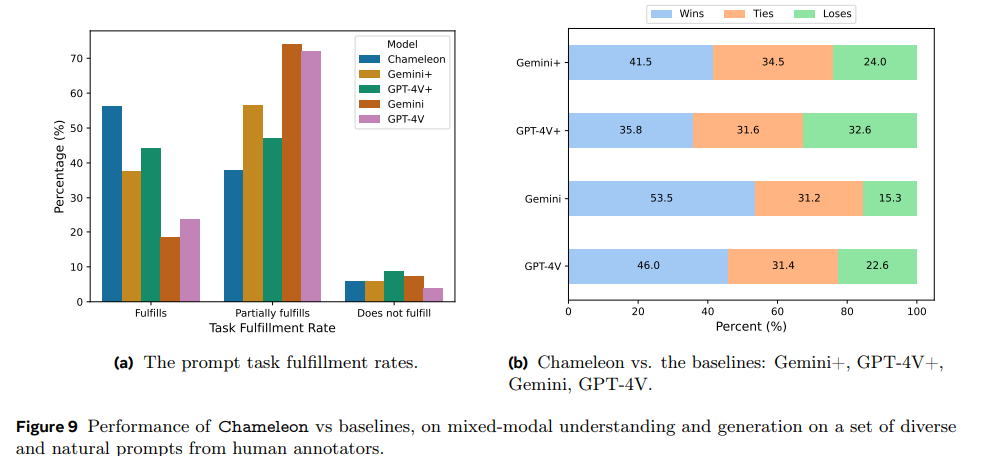
Chamelon 성능2
Text-only Task 에서도 34B 모델로 70B 모델에 견줄만할/뛰어난 성능을 보였다.

Chamelon 성능3
멀티모달 벤치마크 (Image-to-Text, VQA) 에서 좋은 성능을 보였다. VQA2 에서 공개된 모델 중에는 LLava 최신버전이 성능이 많이 높은데, Fine-tuning 어쩌고 저쩌고 하면서 LLava 성능 추가 안 한 이유는 뭐라고 적었음.

'ML&NLP' 카테고리의 다른 글
2024 DoLa NLP Seminar (0) 2024.08.30 UniS-MMC: Multimodal Classification via Unimodality-supervisedMultimodal Contrastive Learning 논문 리뷰 (0) 2024.06.05 E5 Text Embedding 시리즈 논문 및 구현 설명 (0) 2024.03.06 [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning (0) 2023.11.15 Vision-Language Pretrained Model 리뷰 - BLIP, BLIP2 (0) 2023.08.31